NVIDIAは2026年2月17日、日本語に特化した90億(9B)パラメータの言語モデル「NVIDIA Nemotron-Nano-9B-v2-Japanese」をHugging Face上で公開したそうです。ライセンスは「NVIDIA Nemotron Open Model License(Agreement)」で、商用利用も可能です。
同モデルは、NVIDIAが2025年8月18日に公開した「NVIDIA-Nemotron-Nano-9B-v2」をベースに、日本語データセット「Nemotron-Personas-Japan」などで継続事前学習とSFT(教師ありファインチューニング)を施したものだといいます。開発期間は2025年6月から2026年1月で、事前学習データのカットオフは2024年9月です。
推論タスクと非推論タスクの両方をこなす汎用モデルで、AIエージェントやチャットボット、RAGシステムの開発に向くとのこと。
アーキテクチャには、Mamba-2とMLP層を主体にAttention層を4層だけ組み合わせたMamba2-Transformerハイブリッド構造(ネットワークアーキテクチャは「Nemotron-Hybrid」)を採用しています。Transformerのみに依存しない仕組みのため、同サイズのオープンソース代替モデルと比べて最大6倍のスループット向上が見込めるとのことです。コンテキスト長は最大128K(13万1072トークン)で、日本語と英語に対応します。
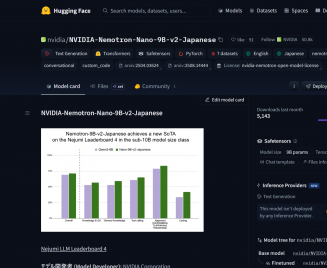
日本語能力の強化にあたり、NVIDIAはWikipedia、fineweb-2 Japanese、aozorabunkoなどの日本語オープンソースコーパスで継続事前学習を実施したそうです。日本のLLM評価プラットフォーム「Nejumi LLM Leaderboard 4」では、10B以下のカテゴリで1位を獲得しています。






