
グーグルは12月6日(現地時間)、新しいAI「Gemini」を発表しました。
音声・テキスト・画像・動画に対応したマルチモーダルAI
Geminiは音声、テキスト、画像、動画など種類の異なる複数の情報を一般化して理解、操作、組み合わせることができるマルチモーダル仕様のAIです。
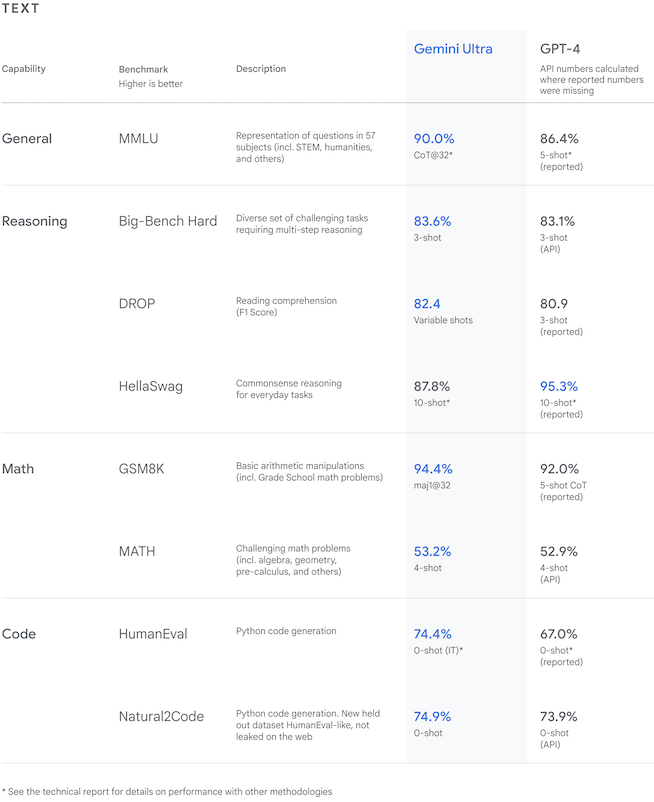
驚くべきはその性能。GeminiはAIに関する32のベンチマークテストのうち30で、既存のAIの性能を上回る成績をマーク。多くの項目でOpenAIの最新モデル「GPT-4」と同等、もしくはそれを超える性能をもっているとGoogleは主張しています。
Googleによるハンズオン動画では、Geminiが映像を理解する様子も公開。目の前に紙が出てくると「机の上に紙が1枚置かれている」述べ、その紙にユーザーがアヒルの絵を描き始めると、最初は「くねくねした線が見える」としか答えられなかったAIが、描き進むに従って形状を認識できるようになり、最後は「鳥のように見える」と回答する様子も。
ただし、この映像は不審な点が指摘されている都合よく編集された映像であり、鵜呑みに出来ない点には注意が必要です。
性能とサイズ別に3バージョンを用意
Geminiは性能とサイズ別に3つのバージョンを用意。使い方に合わせて選択できる仕組みです。
- 「Gemini Ultra」……非常に複雑なタスクに対応できるがサイズも大きい性能重視型(発表されたベンチマーク結果はこちらのモデルのもの)
- 「Gemini Pro」……幅広いタスクに対応できる程度にサイズダウンしたバランス型
- 「Gemini Nano」……携帯端末などに搭載できる超軽量型
3種類のうち、Gemini Proについては同日より生成AI「Bard」の英語版に導入されており、すでにブラウザなどで利用可能です。
Gemini Nanoについても同じく12月6日より、「Pixel 8 Pro」のレコーダーアプリの要約機能など、一部英語版アプリ向けに導入を開始。さらに2024年初頭には、同機種向けに「Assistant with Bard」の提供も予定されていますが、日本語版の提供については未定です。
Google のこれまで
 Google Driveの「消失バグ」、事態収拾に失敗。未解決のままスレッド強制閉鎖へ2023/12/09
Google Driveの「消失バグ」、事態収拾に失敗。未解決のままスレッド強制閉鎖へ2023/12/09 Google Driveでデータが消失。複数ユーザーが報告する深刻な不具合、Googleが調査を開始2023/11/28
Google Driveでデータが消失。複数ユーザーが報告する深刻な不具合、Googleが調査を開始2023/11/28 特価:Googleがブラックフライデー。Pixelなどが値引き2023/11/17
特価:Googleがブラックフライデー。Pixelなどが値引き2023/11/17 お知らせ:Google Newsでのフォローをお願いします2023/11/09
お知らせ:Google Newsでのフォローをお願いします2023/11/09 Armから離脱の動き?QualcommとGoogle、スマートウォッチ向けRISC-Vチップを共同開発2023/10/19
Armから離脱の動き?QualcommとGoogle、スマートウォッチ向けRISC-Vチップを共同開発2023/10/19
 Google Pixel 8 Pro開封。移行円滑、音は相変わらず駄目2023/10/13
Google Pixel 8 Pro開封。移行円滑、音は相変わらず駄目2023/10/13 噂:「Google Pixel 8 Pro」は体温計機能が搭載される?2023/05/22
噂:「Google Pixel 8 Pro」は体温計機能が搭載される?2023/05/22 サムスン、5000万画素の撮像素子「ISOCELL GNK」をこっそり発表。既にPixel 8/8 Proに搭載されている可能性2023/11/10
サムスン、5000万画素の撮像素子「ISOCELL GNK」をこっそり発表。既にPixel 8/8 Proに搭載されている可能性2023/11/10 「Pixel 8 Pro」は「Pixel 7 Pro」より曲げに強くなった?海外YouTuberの耐久テストで判明2023/10/26
「Pixel 8 Pro」は「Pixel 7 Pro」より曲げに強くなった?海外YouTuberの耐久テストで判明2023/10/26 次に期待していい?Pixel 8で搭載「断念」された機能3つが判明2023/10/20
次に期待していい?Pixel 8で搭載「断念」された機能3つが判明2023/10/20


