演技する音声AI、降臨。
Googleが新しい音声合成モデル「Gemini 3.1 Flash TTS」を発表しました。Google公式ブログが2026年4月15日に伝えています。
最大の売りは、テキスト本文に英語の角括弧タグとして「audio tags」を直接埋め込むことで、話し方・テンポ・抑揚・アクセントを細かく操れる点です。たとえば「[whisper]」と書けばその部分だけささやき声に、「[short pause]」で間を差し込めます。しかも対応言語は70以上。同じ台本を多言語で展開しやすい設計です。
audio tagsは、音声ディレクターが俳優に渡す「ト書き」を本文に書き込む感覚に近い機能です。Google公式ブログによると、シーン設定や話者ごとの指示、文中での表現切り替えを組み合わせることで、キャラクター性や没入感のある音声体験を作れるとのこと。
もうひとつ嬉しいのが、ネイティブなマルチスピーカー対話への対応です。公式ドキュメントでは最大2人の話者を設定でき、ポッドキャスト風の掛け合いを生成できます。一方で、このTTSはあくまで正確なテキスト読み上げ向けで、双方向の音声エージェント用途はLive APIという別系統が担う構成です。安全面でも抜かりなく、全生成音声にSynthIDが埋め込まれます。
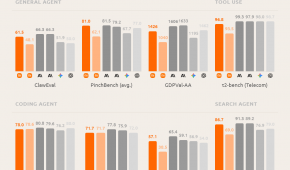
第三者評価のArtificial Analysis TTS leaderboardではEloスコア1211を記録しました。公開順位ではInworld TTS 1.5 Maxに次ぐ位置で、Eleven v3を上回っています。
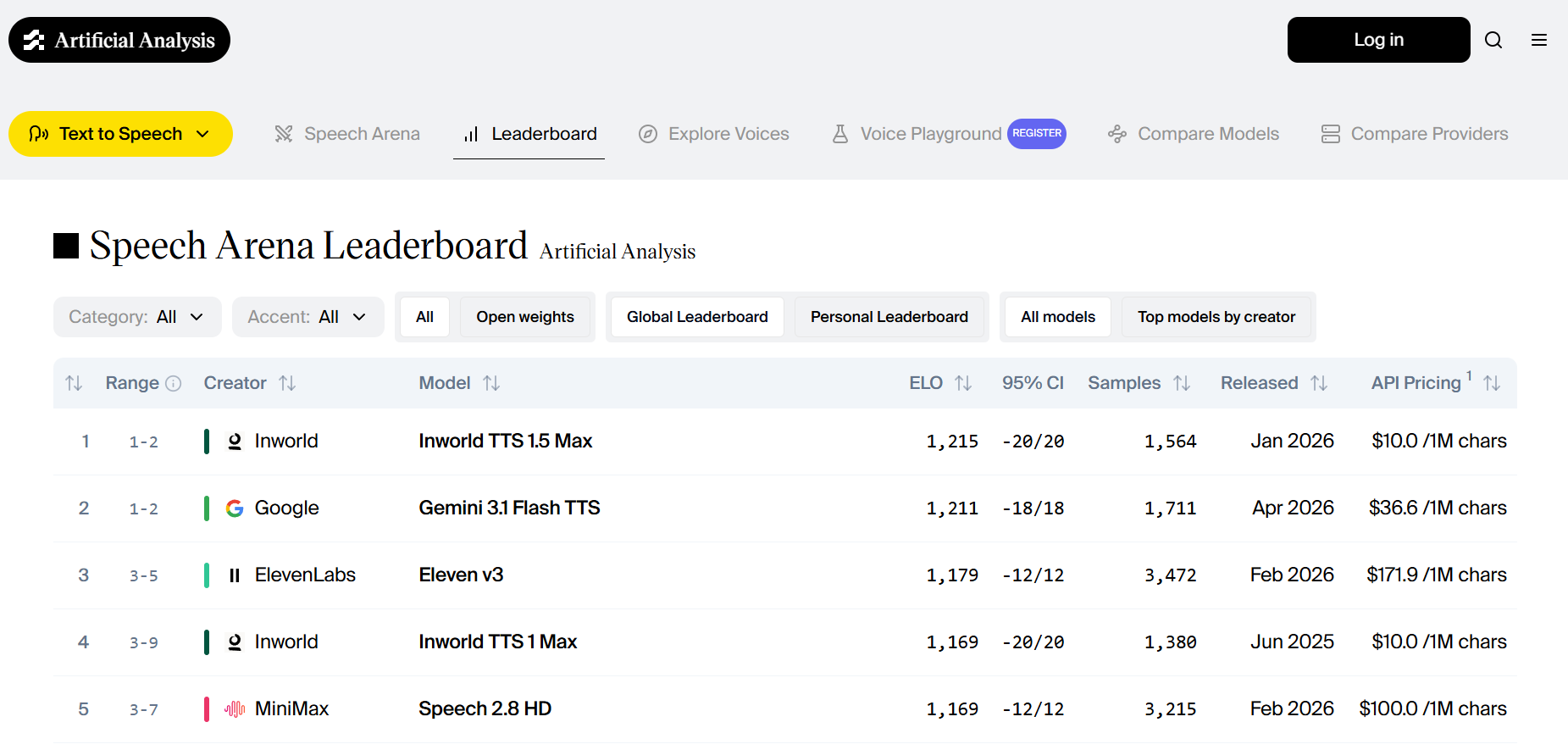
価格はGemini Developer APIの有料ティアで、標準料金がテキスト入力100万トークンあたり1ドル、音声出力100万トークンあたり20ドル、バッチ料金がそれぞれ0.5ドルと10ドルです。
提供先は、開発者向けにGemini APIとGoogle AI Studioでプレビュー、企業向けにVertex AIでプレビュー、Workspaceユーザー向けにはGoogle Vids経由です。動画ナレーションやキャラクター音声の試作など、用途の幅が広がりそうです。
読み上げAIは、流暢さだけでなく演出のしやすさでも差がつく段階に入ってきました。ささやき声や間の取り方までテキストで指示できるようになったことで、音声制作の試作やローカライズの効率化が一段と進みそうです。
Google のこれまで
 【超朗報】ついにきた!「戻る」押しても戻れないクソサイト、スパムとしてGoogle検索から削除へ2026/04/14
【超朗報】ついにきた!「戻る」押しても戻れないクソサイト、スパムとしてGoogle検索から削除へ2026/04/14 Google、スマートホーム向け「Gemini for Home」日本で早期アクセス開始2026/04/09
Google、スマートホーム向け「Gemini for Home」日本で早期アクセス開始2026/04/09 Google、作曲AI「Lyria 3 Pro」発表、AIで最大3分の楽曲生成が可能に2026/04/02
Google、作曲AI「Lyria 3 Pro」発表、AIで最大3分の楽曲生成が可能に2026/04/02 Suno対抗の「AI音楽」Producer、Googleが買収。2026/03/30
Suno対抗の「AI音楽」Producer、Googleが買収。2026/03/30 AIとの会話から「沈黙」が消える。Googleの新リアルタイム音声モデル「Gemini 3.1 Flash Live」発表2026/03/29
AIとの会話から「沈黙」が消える。Googleの新リアルタイム音声モデル「Gemini 3.1 Flash Live」発表2026/03/29
 Gemini「Personal Intelligence」日本提供開始、Gmailや写真と連携し個別最適化2026/04/16
Gemini「Personal Intelligence」日本提供開始、Gmailや写真と連携し個別最適化2026/04/16- Google、スマートホーム向け「Gemini for Home」日本で早期アクセス開始2026/04/09
- AIとの会話から「沈黙」が消える。Googleの新リアルタイム音声モデル「Gemini 3.1 Flash Live」発表2026/03/29
 Appleの計画が判明?Geminiを「蒸留」してiPhone上で直接動作させる2026/03/27
Appleの計画が判明?Geminiを「蒸留」してiPhone上で直接動作させる2026/03/27 サムスンがGeminiとカメラ搭載の「Galaxy Glasses」を開発か?2026/03/22
サムスンがGeminiとカメラ搭載の「Galaxy Glasses」を開発か?2026/03/22