Cursorの独自モデル、また一段ギアを上げてきた。
Cursorは、AIコーディングエディタのCursorが自社製エージェントモデル「Composer 2.5」を公開しました。前バージョンComposer 2と比べて長時間タスクの粘り強さ、複雑な指示への追従性、共同作業のしやすさが大幅に改善したとのことです。
ベースになっているのは、前バージョンと同じMoonshot AIのオープンソースチェックポイント「Kimi K2.5」系。そこにCursorが独自の追加学習と強化学習を重ねた構成になります。学習面では、より難しいRL(強化学習)環境の投入、長いロールアウトの中で問題地点に直接テキストでフィードバックを与える「targeted RL with textual feedback」、そしてComposer 2と比べて25倍に増やした合成タスクなどを採り入れたと説明しています。
targeted RL with textual feedbackは、AIに長い作業をやらせきった後にまとめて採点するだけではなく、問題が起きたターンの文脈に短いヒントを差し込み、そのヒント入りの出力分布を教師として学習させるやり方です。たとえるなら、新人エンジニアの作業に対して、最後の総評だけでなく、ミスした箇所ごとに赤入れを残すイメージ。失敗の原因がぼやけにくく、学習効率が上がりやすいというわけです。
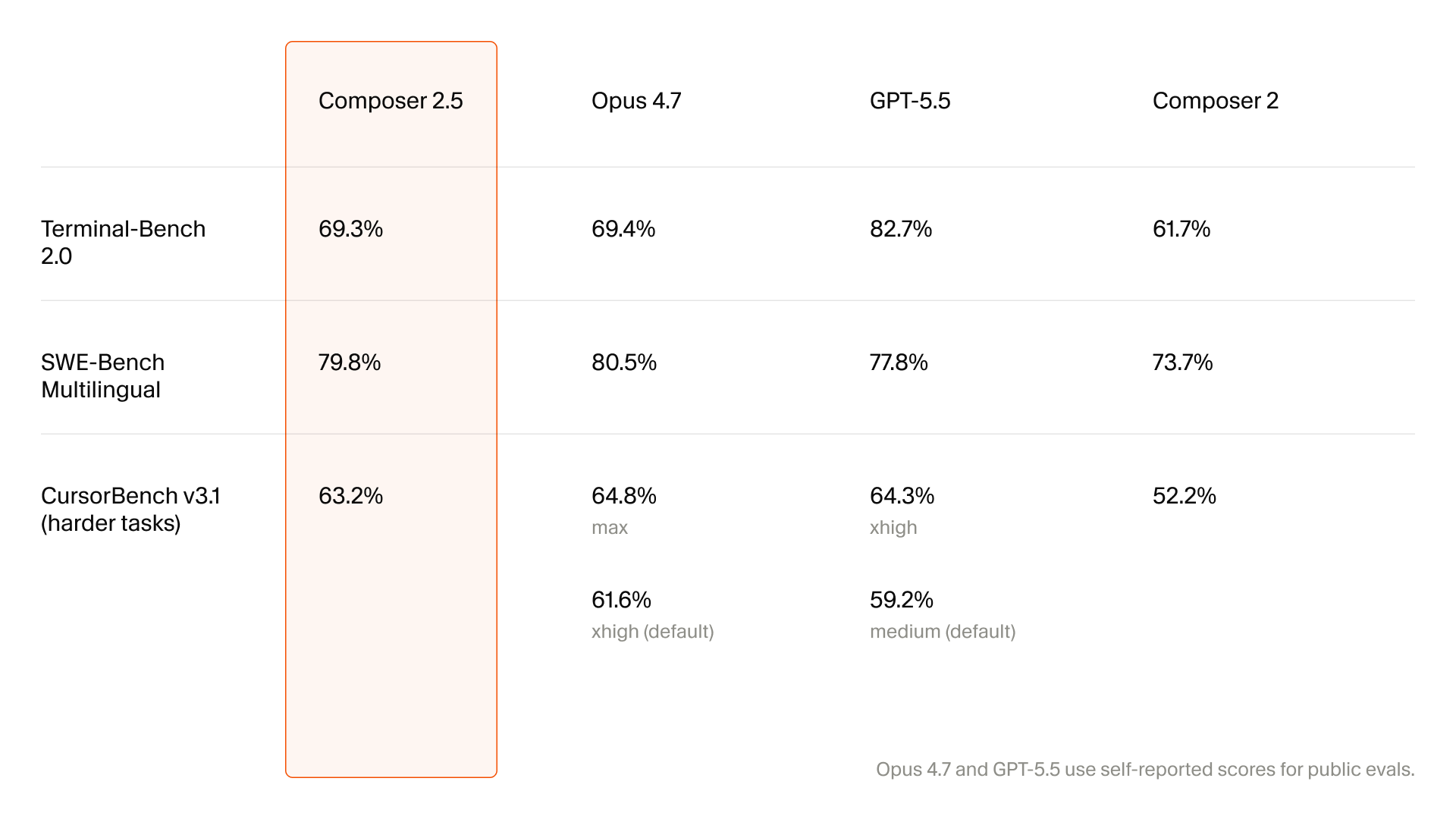
なお性能はあくまでベンチマークテストではOpus 4.7やGPT 5.5に並ぶものに。
料金は2段階です。標準版が入力100万トークンあたり0.50ドル、出力2.50ドル。応答速度を優先したFast版は入力3.00ドル、出力15.00ドルで、Cursor上ではFastがデフォルトになります。効率的と謳っており、コスパも良さげです。さらに公開初週はComposer 2.5の利用枠が2倍になる扱いです。なかなか気合の入った売り出し方ですね。

Cursorは4月にSpaceXとのモデル学習提携も明らかにしており、今回の発表でもその次世代計画に改めて触れました。xAIのColossusインフラ(Composer 2.5の発表本文では「Colossus 2」と表記)の100万H100相当の計算能力を使い、次世代のより大きなモデルをゼロから学習する方針です。次世代モデルの学習に10倍の総計算量を使う計画だそうです。次に作る大型モデルへ投入する計算リソースの話なので、今回のモデルじゃないのは注意ですね。
GitHub CopilotやClaude Code、Windsurfといった競合がひしめく中、Cursorが打つ新しい手。ベンチマークスコアよりも、長時間のエージェント作業でどれだけ粘り強く動けるかに注目しましょう。
SpaceX のこれまで
 xAI解散、SpaceXのAI部門「SpaceXAI」に統合へ2026/05/07
xAI解散、SpaceXのAI部門「SpaceXAI」に統合へ2026/05/07 SpaceXがxAI買収!Xが孫会社に2026/02/03
SpaceXがxAI買収!Xが孫会社に2026/02/03 auスマホ、SpaceXのスターリンク衛星で「直接通信」可能に!2024年内開始予定2023/08/30
auスマホ、SpaceXのスターリンク衛星で「直接通信」可能に!2024年内開始予定2023/08/30 ロケット噴射も耐える!SpaceXが海上インターネット「Starlink Maritime」展開2023/04/20
ロケット噴射も耐える!SpaceXが海上インターネット「Starlink Maritime」展開2023/04/20 「低軌道衛星」からの電波で災害時も繋がるauに―KDDIがSpaceXの衛星通信Starlinkと提携2021/09/13
「低軌道衛星」からの電波で災害時も繋がるauに―KDDIがSpaceXの衛星通信Starlinkと提携2021/09/13
- xAI解散、SpaceXのAI部門「SpaceXAI」に統合へ2026/05/07
 【悲報】マスク氏のAI企業「xAI」、共同創業者11人が全員離脱2026/03/30
【悲報】マスク氏のAI企業「xAI」、共同創業者11人が全員離脱2026/03/30 xAI「Grok 4.20 Beta」公開、知能スコア48で毎秒265トークンの高速出力2026/03/14
xAI「Grok 4.20 Beta」公開、知能スコア48で毎秒265トークンの高速出力2026/03/14- SpaceXがxAI買収!Xが孫会社に2026/02/03
 xAI、「反抗的性格のAI」Grokを発表。X Premium+で利用可能に2023/11/05
xAI、「反抗的性格のAI」Grokを発表。X Premium+で利用可能に2023/11/05
 【悲報】Cursorが本番DBを9秒で削除する事故が発生。2026/05/02
【悲報】Cursorが本番DBを9秒で削除する事故が発生。2026/05/02 【衝撃】スペースX、9.6兆円でAIエディター「Cursor」買収へ!?2026/04/22
【衝撃】スペースX、9.6兆円でAIエディター「Cursor」買収へ!?2026/04/22 AIコーディングツール「Cursor」急成長 年換算売上が3か月で倍増2026/03/25
AIコーディングツール「Cursor」急成長 年換算売上が3か月で倍増2026/03/25 Cursor、AIエージェントを自動起動する新機能「Automations」を公開2026/03/13
Cursor、AIエージェントを自動起動する新機能「Automations」を公開2026/03/13 Cursor、月額$200の上位プラン「Ultra」を発表 従来Proプランの20倍使用可能2025/06/18
Cursor、月額$200の上位プラン「Ultra」を発表 従来Proプランの20倍使用可能2025/06/18