
ラズパイでもAIエージェントが走る!
Google DeepMindは、映像や音声の理解もできるマルチモーダルAIの「Gemma 4」ファミリーを発表しました。
Gemma 4はE2B、E4B、26B A4B MoE(推論時に約4BをアクティブにするMixture of Experts)、31B Denseの4サイズ展開。31Bモデルは4月1日時点のArena AI text leaderboardでオープンモデル3位、26Bモデルは6位だそうです。エッジ向けモデルは12万8000トークン、大型モデルは25万6000トークンのコンテキストに対応します。なお「最大4倍高速」「バッテリー消費は最大60%削減」は、Android向けAICore Developer Previewで示されている数値とのことです。
注目はオンデバイスでのAIエージェント機能です。マルチステップの計画立案、自律的なアクション実行、オフラインでのコード生成、画像処理、そしてE2B/E4Bでは音声処理まで、オンデバイスでこなせるといいます。もっとも、Agent Skillsの例にはWikipedia照会や他モデル連携も含まれているため、あらゆる処理が常にネット不要とまでは言い切れません。
「AIエージェント」とは、ユーザーの指示を受けて自分で考え、複数の手順を踏んで目的を達成してくれるAIのこと。つまり「調べて、判断して、実行する」をまとめて引き受ける賢いアシスタントで、それをクラウド任せではなく手元の端末でも回せるのが今回のポイントです。
そして偉いのは、今回のGemma 4シリーズはApache 2.0ファミリーで提供されているということ。Gemma 3は先駆者であるMetaのLlamaに倣ってか、やや複雑な独自ライセンスを採用。対する中国勢はアリババグループのQwenを筆頭に、かなり自由度の高いApache 2.0やMITライセンスでモデルを公開することが多く、企業内での試しやすさが段違いでしたが、Gemmaもこれに追従してきた形となります。
対応ハードウェアの幅もかなり広めです。Android/iOSのスマホはもちろん、Windows、Linux、macOS、WebGPU経由のブラウザ、Raspberry Pi 5、Qualcomm IQ8 NPU、NVIDIAのRTX GPU、Jetson Orin Nanoなどが挙げられています。LiteRT-LMのベンチマークでは、Raspberry Pi 5上のGemma 4 E2Bでprefill 133トークン/秒、decode 7.6トークン/秒を記録したそうです。
Google AI Edge Galleryアプリ(iOS/Android対応)では4月2日からAgent Skillsを試せます。AndroidのAICore Developer Preview経由での組み込みにも対応。Googleによると、いまGemma 4向けに書いたコードは年内登場予定のGemini Nano 4対応デバイスでもそのまま動く見込みだそうです。加えて、NVIDIAもRTX向け最適化を発表済みで、Ollamaやllama.cppを使ったローカル実行も案内されています。
Apache 2.0ライセンスのオープンモデルとして、モバイルやIoTからハイエンドGPUまでカバーするGemma 4。オンデバイスAIの裾野は、かなり広がりそうです。
主要スペックを整理すると、以下のとおりです。
| モデル | 方式 | パラメータ | コンテキスト長 | 対応モダリティ |
|---|---|---|---|---|
| Gemma 4 E2B | Dense | 有効 2.3B(埋め込み込み 5.1B) | 128K | Text / Image / Audio |
| Gemma 4 E4B | Dense | 有効 4.5B(埋め込み込み 8B) | 128K | Text / Image / Audio |
| Gemma 4 26B A4B MoE | MoE | 総 25.2B / Active 3.8B | 256K | Text / Image |
| Gemma 4 31B Dense | Dense | 30.7B | 256K | Text / Image |
補足すると、31Bは4月1日時点のArena AI text leaderboardでオープンモデル3位、26Bは6位です。Pi 5でのLiteRT-LM実測はE2Bでprefill 133トークン/秒、decode 7.6トークン/秒。E2Bの1.5GB未満での動作は一部デバイス条件付き、Android側の「最大4倍高速・最大60%省電力」はAICore Developer Preview文脈での数値です。
Google のこれまで
 Google、作曲AI「Lyria 3 Pro」発表、AIで最大3分の楽曲生成が可能に2026/04/02
Google、作曲AI「Lyria 3 Pro」発表、AIで最大3分の楽曲生成が可能に2026/04/02 Suno対抗の「AI音楽」Producer、Googleが買収。2026/03/30
Suno対抗の「AI音楽」Producer、Googleが買収。2026/03/30 AIとの会話から「沈黙」が消える。Googleの新リアルタイム音声モデル「Gemini 3.1 Flash Live」発表2026/03/29
AIとの会話から「沈黙」が消える。Googleの新リアルタイム音声モデル「Gemini 3.1 Flash Live」発表2026/03/29 Googleが量子時代に備え本気の暗号刷新。Android 17のセキュリティ強化がヤバすぎる2026/03/27
Googleが量子時代に備え本気の暗号刷新。Android 17のセキュリティ強化がヤバすぎる2026/03/27 【朗報】グーグル、新OS「Aluminium OS」開発中2026/04/05
【朗報】グーグル、新OS「Aluminium OS」開発中2026/04/05
 爆発的に広がる危険なAI「OpenClaw」、NVIDIAが安全策「NemoClaw」を発表2026/03/22
爆発的に広がる危険なAI「OpenClaw」、NVIDIAが安全策「NemoClaw」を発表2026/03/22 NVIDIA、なんとNVIDIAチップ不要のAIエージェントNemoClaw発表か?2026/03/12
NVIDIA、なんとNVIDIAチップ不要のAIエージェントNemoClaw発表か?2026/03/12 【悲報】NVIDIA、中国向けチップ生産停止。2026/03/08
【悲報】NVIDIA、中国向けチップ生産停止。2026/03/08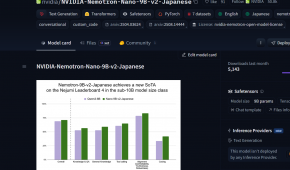 NVIDIAが日本語特化の9Bモデル「NVIDIA Nemotron-Nano-9B-v2-Japanese」を公開2026/02/21
NVIDIAが日本語特化の9Bモデル「NVIDIA Nemotron-Nano-9B-v2-Japanese」を公開2026/02/21 NVIDIAが2026年の新型ゲーミングGPU投入を延期か?約30年ぶりの「空白年」2026/02/16
NVIDIAが2026年の新型ゲーミングGPU投入を延期か?約30年ぶりの「空白年」2026/02/16






